
1.1 Turn Data Into Profit
The Decision Support System (DSS) marketplace is in a tremendous growth stage today because of the availability of affordable, UNIX® based servers to house increasingly larger volumes of data. Businesses are in a highly competitive global marketplace. In order to compete effectively, they must be able to analyze business data and turn it to their competitive advantage FAST. Business opportunity windows are shrinking -- speed is of the essence.
This is even more apparent in marketing environments. Mass marketing is expensive and returns less on investment than smarter, more focused market segmentation. A top national ad agency recently made the statement that we are returning to the era of one to one (1:1) marketing, where successful companies focus on the individual customer's needs and buying patterns. Therefore, Decision Support Systems need to include not only demographic data such as address, occupation, etc., but also psychographic information, such as customer profiling, that can be extrapolated to prospects. This need has led many companies to create a specific type of Decision Support System, the Marketing Database (MDB).
In the past, historic data was often ignored. The cost of keeping such information was
prohibitive. But, with the increasing availability of cost-effective hardware and the adoption of open systems, marketing organizations can now afford to retain the types of information required for an MDB. In fact, this has become a requirement in order to be competitive in today's business environment.
How are people building such systems? They are combining open systems UNIX platforms and inexpensive disk storage with off-the-shelf software such as Relational Database Management Systems (RDBMS) for the underlying platform, desktop programs for providing easy access to information using statistical, analytic and reporting tools.

1.2 A New Information Processing Paradigm
Decision Support Systems are heuristic in nature; that is, they stimulate investigation or research. One query raises questions to stimulate another, etc. In an operational database such as a financial accounts receivable or order entry system, reporting needs are fairly static. Management and users are more concerned with the format of the data rather than what-if type analyses. In the typical DSS, formatting is a subordinate issue. Instead, there is a need to discover the meaning of the data, to explore the database. This requires new functionality, such as the ability to drill down to regions of interest and then use this information to spot trends. For example:
-

How many customers in the database have characteristic A?
Based on that answer set, how are they spread geographically?
The first question is exploratory; the second question is analytic. Are there any tools available that can support these new business needs? To do so in SQL is a nightmare. Additionally, even if such off the shelf software packages exist, large amounts of processing time are required, especially as the database grows. In the above example, the two queries are entirely separate and unleveraged. In other words, the second query does not search the answer subset from the first query, but rather re-executes the query against the entire database. This contributes to the basic sluggishness of decision support technology, and has often led to the failure of companies to implement successful Decision Support Systems.
When using a DSS database to discover important trends and information, a high response speed is critical to support the user's continuing train of thought. If the system is too slow, people will give up and begin to make assumptions and extrapolations based on incomplete evidence and data analysis. This tends to increase the odds of making poor decisions.
There are several main factors that contribute to unacceptably slow DSS response rates:
-
 Large quantities of data in the database cause enormous I/O demands to satisfy the query.
Large quantities of data in the database cause enormous I/O demands to satisfy the query.
These databases usually have several tables with millions of rows.
Complex queries often consist of multiple table joins.
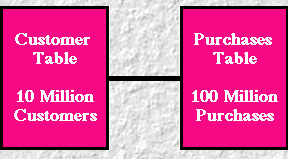
EXAMPLE.
A direct marketer has as many as 10 million customers in a database. The
database has 100 million items purchased by those customers. A query such as
"How many customers bought Product XYZ from us?" can take several minutes to execute.
 Even a simple query such this can generate large amounts of I/O in order to answer. However, it does not stop there. Because it is heuristic, a DSS could trigger other queries in the user's mind. And, if we have asked only how many, we have not yet created a viable answer set. If we next ask,
Even a simple query such this can generate large amounts of I/O in order to answer. However, it does not stop there. Because it is heuristic, a DSS could trigger other queries in the user's mind. And, if we have asked only how many, we have not yet created a viable answer set. If we next ask,
-
Out of those customers who bought Product XYZ, how many live in New Jersey or Pennsylvania?
then this new query causes a re-execution of the first database search. With a little imagination, one can see how increasingly complex queries submitted by many users can quickly multiply to create significant demands on the DSS.
Another problem for the RDBMS involves queries with low cardinality fields (i.e., fields with a low number of possible values, such as gender) for example:
 How many customers are women?
How many customers are women?
Even such a simple query with low cardinality constraints can send the RDBMS software into a tailspin. Off-the-shelf RDBMS packages have a one-size-fits-all strategy for indexing -- the balanced tree (B-tree) index. B-trees are good for on-line transaction processing (OLTP) applications, as they work well when finding a small number of rows in response to a query. But, they do not work well for Decision Support/Marketing Warehouse type systems. A DSS requires answers for groups of objects, not just answers about a few objects. B-trees are an excellent choice for high cardinality fields (columns) such as social security number. However, the standard, out of the box RDBMS with B-tree-only indexing is not enough to service the high performance requirements of a marketing database warehouse system.
In the world of open systems, RDBMS databases are the de facto standard for implementing DSS warehouses. The ideal DSS solution is one that provides both the speed and analytic functionality not found in the underlying RDBMS software. This state-of-the-art solution is available today with The Information Retrieval Engine (IRE(TM)) Marketing Warehouse from Mercantile Software Systems, Inc.
The IRE (TM) Marketing Warehouse leverages the customer's investment by allowing the company to use existing data. And this is done in a way that does not invade the existing operational systems. By augmenting the database indexes with special indexes, the IRE (TM) Marketing Warehouse provides extremely high-speed searches. We also add a full complement of Boolean querying and N-dimensional profiling for DSS analyses.
[ Jump to Mercantile Software Systems' Web Site ]
Mercantile Software Systems, Inc.
371 Hoes Lane - Suite 102, Piscataway, NJ 08854 - (908) 981-1290 - email: Sales@mss.com
Copyright ©1995 Mercantile Software Systems, Inc. All Rights Reserved.